
Data Science Interview Question(TOPIC WISE-PART-1)
Hi guys, I am starting a series of blogs where we will discuss most frequently asked questions in data science interviews and that too topic wise, At the end of the series you will get around 100–150 questions which you can revise before going to any interview.
So the first topic will be…
Random Forest Algorithm
Random Forest Algorithm is a very important algorithm with respect to data science interviews. Let’s discuss the frequently asked questions from Random Forest.
Question—1 What do you mean by ensemble techniques?
Ans-1 Ensemble means group, the word has come from “An Ensemble of musicians” where multiple musicians with different instruments work together for one song.
Likewise, when we use different machine learning techniques like Logistics Regression, Linear Regression, and SVMs to solve one business problem, that’s called the ensemble technique.
Types of Ensemble models are…
- Bagging
- Boosting
- Stacking
- Cascading
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Question—2 What is Bagging?
Ans-2 Bagging stands for Bootstrap Aggregation.
Bagging has two components
- Bootstrap
- Aggregation
Let’s us understand each component one by one…
Bootstrap
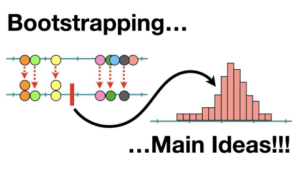
Lets understand bootstrapping by a simple example, let’s say I have data of 1000 rows, (R1,R2,R3…..R1000) R1 stands for row1, and so on.
Every row has 5 different columns(C1,C2,C3,C4,C5). Now if i start taking random samples from rows, let’s say i take a Sample1(S1) of 100 rows out of 10000 in which I got,
S1-{R1,R6,R5,R80,R1,R5,……} → total 100 rows
You can observe that we are using sampling with replacement, where i row can be repeated any number of times.
Likewise, let’s say we take 30 such samples (S1,S2,S3,S4…..S30) with 100 random rows in each sample.
Now imagine, if i apply one ML technique to one sample, and another ML technique to another sample, at the end we will have 30 ML models.
Assume this problem to be a simple Spam Classifier, now 30 ML models will predict different answers, for example
S1 →Model_1 →Prediction SPAM
S2 →Model_2 →Prediction NOT SPAM
S3 →Model_3 →Prediction SPAM
.
.
S30 →Model_30 →Prediction NOT SPAM
Out of 30, let’s say 20 are predicting “Spam” and 10 are predicting “Not Spam”. Then how should be decided, here comes the second component which is “AGGREGATION”
We will aggregate all the models, if its a classification problem, then we will take simple MAJORITY VOTE, (class with the maximum number will be predicted, class)
If it’s a regression problem, we will simply take the Median or Mean of the values and the median/ mean value will be the predicted value.
Question -3 Explain the random forest algorithm.
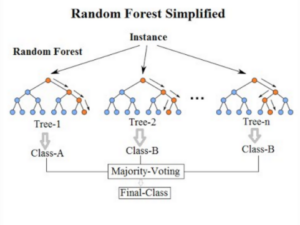
Ans-3 Random forest algorithm actually is an ensemble technique called boosting with a slight twist.
Random Forest is Simply…
[Decision Tress as Base Learners+Bagging+Column Sampling]
Now bagging can be written Bootstrap + Aggregation as mentioned above. [Decision Tress as Base Learners+Bootstrap+Aggregation+Column Sampling] Now Bootstrap is nothing but sampling with replacement/Row Sampling
[Decision Tress as BaseLearners+RowSampling+Aggregation+Column Sampling]
So simply take the data, do the row sampling with replacement, do the column sampling(select random features), for every sample train a decision tree, train “k” such models, k is a hyperparameter, then simply aggregate the result from every model.
Thats simply a Random Forest…
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Question— 4 Can we use Random Forest for Regression also, How?
Ans-4 Yes, we can use random forest for regression, At the time of aggregation just take the mean/ median for regression and take the majority vote for classification.
for example, let’s assume you have a regression problem and the value of k=5, means you have 5 models, 5 decision trees.
Let’s assume,
DT-1 predicting the value y1
DT-2 predicting the value y2
DT-3 predicting the value y3
DT-4 predicting the value y4
DT-5 predicting the value y5
So the final prediction for random forest is the mean of all the predictions from the decision trees. Final_Prediction=y1+y2+y3+y4+y5/5
That’s how random forest works for regression.
Now let’s assume you have a classification problem and the value of k=5, means you have 5 models, 5 decision trees.
Let’s assume its a Spam/Not Spam Prediction
DT-1 predicting the value SPAM
DT-2 predicting the value SPAM
DT-3 predicting the value SPAM
DT-4 predicting the value NOT SPAM
DT-5 predicting the value NOT SPAM
So the final prediction for random forest is the MAJORITY VOTE from all the predictions from the decision trees.
Final_Prediction= SPAM as it got 3 votes out of 5.
Question —5 What is Randomisation for Regularisation and How we achieve that in Random Forest?
Ans-5 Randomisation for Regularisation is a technique to reduce the variance from the data. High Variant data leads to overfitting which gives good performance on the training data and performance significantly drops on the testing data.
Now RFR is a concept by which the whole data gets divided into multiple samples, the data points which were creating a variance in the data also got distributed into multiple samples, so the intensity of those points to one model now gets distributed to multiple models, hence creating a less variance space. Also when you are aggregating the results from different models, you are not dependent on just one model, you are giving equal weightage to every model prediction there by reducing the overall variance of the model.
RFR also works for Drop Out in Multi Neural Perceptron.
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Question—6 What is the Run time complexity for Random Forest?
Ans-6 Run time complexity of a random forest with “K” decision trees and each decision tree of “D” depth is O(K*D)
Question —7 What are the limitations of the Random Forest Algorithm?
Ans-7 Limitations of random forest are…
- Random Forest does not work well for sparse data.
- Random forest works only better on tabular data, when it comes to text data, it does not perform well.
- If the data is not axis aligned, Random forest wont work well.
Question—8 What are the hyperparameters in Random Forest?
Ans-8 Hyperparameters in Random Forest are…
- K(Number of samples)
- D(Depth of the tree)
So that was it for the random forest, There could be lot of other questions with respect to the experience of the candidate.
Also see how to write simple code of random forest through sklearn, and also see how to tune the hyperparameters.
Author:
Call the Trainer and Book your free demo Class Call now!!!
| SevenMentor Pvt Ltd.
© Copyright 2021 | Sevenmentor Pvt Ltd.