
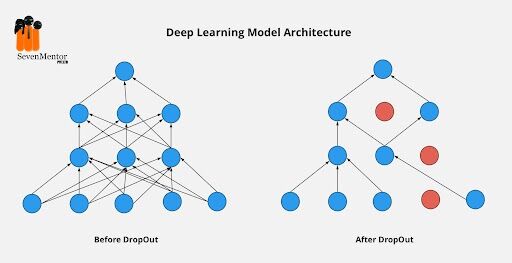
Dropout Layers –
Nowadays deep learning, every data scientist should have used the dropout layer at a particular moment in his or her full career of building neural networks. Now the question is why dropout is so common? How does it work internally? What is the problem to solve? Is there any another option to drop out? If you have familiar with these similar questions about dropout layers, then you are here You will discover the math behind the most important dropout layers. After this, you will be able to give answers related to these different queries about dropout and if you have eager to know about this, so should learn an advanced version of dropout layers. Now let’s understand the first question. What is the problem that we have and we are trying to solve? The deep neural networks have various architectures, may be very deep, and trying to generalize this model on the given dataset. But it is too hard to learn different features from the dataset, they can learn noise in the dataset. This can improve the model performance or accuracy on the training dataset but low performance on new data points (test dataset). This is problem is called overfitting. To handle this problem, we have a regularisation technique that penalizes the weights or the bias of the neural network but this is not enough.
For Free, Demo classes Call: 7507414653
Registration Link: Click Here!
The way to handle overfitting is to regularize the model and get the average predictions also using all possible settings of the various parameters and do the aggregation of the final output. But this leads to much computationally expensive It is not feasible for a real-time inference or prediction. Another option is inspired by using ensemble techniques like random forest and XGboost where we are going to join or merge multiple neural networks of the same or different architectures. But this should have multiple models to be trained and have to stored and becomes challenging to learn networks and go deeper. And we have a solution known as Dropout Layers In the overfitting problem, our model may learn the statistical noise. To be precise and accurate, the main focus of training and is to minimize the loss function as much as possible and in overfitting, a unit is likely to change such that that fixes up the mistakes of the other units. This introduces complex co-adaptations, which leads to the overfitting problem in our model because this complex co-adaptation is not good to generalize on other or training datasets. Suppose, if we use dropout, it surely prevents these units to handle the mistake of other units, so by preventing co-adaptation, for every iteration the presence of a single unit is highly unreliable. Now by randomly dropping layers, it forces to neural network layers to take more or less responsibility. And also, for the input by taking a probabilistic approach. In the implementation of the dropout layer, during training neural network, a unit in a layer is selected with a having a probability that is 1-drop probability. This will create a thinner architecture in the given training period and every time this architecture may be different.
For Free, Demo classes Call: 7507414653
Registration Link: Click Here!
The dropout concept works mathematically but has a problem during the prediction? So how do we use the neural network with dropout and other remove the dropout during inference? According to Geoffrey Hinton, Way to Prevent Neural Networks from Overfitting is an event inspired by the concept of the fundamental dropout.
The analogy of one of the famous search engines Google Brain is considerable because it learns a large ensemble of models. In neural networks, it may not seem very efficient use of hardware since the same features need to be inspected separately by the different models.
This is a concept that arise when the idea of using the same subset of neurons was invented.
Examples are:
Bank Teller: In this scenario, the tellers are likely to keep changing it regularly because it’s needed to keep the cooperation between the employees and to find out it successfully defrauds the bank.
This idea of randomly selecting different neurons and every iteration with a different set of neurons become successful and useful. The neurons are unable to learn the co-adaptations also preventing overfitting means it same as preventing conspiracies in a particular bank.
For Free, Demo classes Call: 7507414653
Registration Link: Click Here!
Sexual Reproduction: We are considering half of the genes of one parent and also half of the other also it adds a very small amount of random mutation to produce an offspring. We are going to create a mixed ability of the genes and it will be more robust. This is likely to link to a dropout to break co-adaptations.
Author:-
Suraj Kale
Call the Trainer and Book your free demo class
Call now!!! | SevenMentor Pvt Ltd.
© Copyright 2021 | Sevenmentor Pvt Ltd.